import taichi as ti
ti.init(arch=ti.gpu)
use_mc = False
mc_clipping = False
pause = False
# Runge-Kutta order
rk = 1
n = 512
x = ti.field(ti.f32, shape=(n, n))
new_x = ti.field(ti.f32, shape=(n, n))
new_x_aux = ti.field(ti.f32, shape=(n, n))
dx = 1 / n
inv_dx = 1 / dx
dt = 0.05
stagger = ti.Vector([0.5, 0.5])
@ti.func
def Vector2(x, y):
return ti.Vector([x, y])
@ti.func
def inside(p, c, r):
return (p - c).norm_sqr() <= r * r
@ti.func
def inside_taichi(p):
p = Vector2(0.5, 0.5) + (p - Vector2(0.5, 0.5))*1.2
ret = -1
if not inside(p, Vector2(0.50, 0.50), 0.55):
if ret == -1:
ret = 0
if not inside(p, Vector2(0.50, 0.50), 0.50):
if ret == -1:
ret = 1
if inside(p, Vector2(0.50, 0.25), 0.09):
if ret == -1:
ret = 1
if inside(p, Vector2(0.50, 0.75), 0.09):
if ret == -1:
ret = 0
if inside(p, Vector2(0.50, 0.25), 0.25):
if ret == -1:
ret = 0
if inside(p, Vector2(0.50, 0.75), 0.25):
if ret == -1:
ret = 1
if p[0] < 0.5:
if ret == -1:
ret = 1
else:
if ret == -1:
ret = 0
return ret
@ti.kernel
def paint():
for i, j in ti.ndrange(n * 4, n * 4):
ret = 1 - inside_taichi(Vector2(i / n / 4, j / n / 4))
x[i // 4, j // 4] += ret / 16
@ti.func
def velocity(p):
return ti.Vector([p[1] - 0.5, 0.5 - p[0]])
@ti.func
def vec(x, y):
return ti.Vector([x, y])
@ti.func
def clamp(p):
for d in ti.static(range(p.n)):
p[d] = min(1 - 1e-4 - dx + stagger[d] * dx, max(p[d], stagger[d] * dx))
return p
@ti.func
def sample_bilinear(x, p):
p = clamp(p)
p_grid = p * inv_dx - stagger
I = ti.cast(ti.floor(p_grid), ti.i32)
f = p_grid - I
g = 1 - f
return x[I] * (g[0] * g[1]) + x[I + vec(1, 0)] * (
f[0] * g[1]) + x[I + vec(0, 1)] * (
g[0] * f[1]) + x[I + vec(1, 1)] * (f[0] * f[1])
@ti.func
def sample_min(x, p):
p = clamp(p)
p_grid = p * inv_dx - stagger
I = ti.cast(ti.floor(p_grid), ti.i32)
return min(x[I], x[I + vec(1, 0)], x[I + vec(0, 1)], x[I + vec(1, 1)])
@ti.func
def sample_max(x, p):
p = clamp(p)
p_grid = p * inv_dx - stagger
I = ti.cast(ti.floor(p_grid), ti.i32)
return max(x[I], x[I + vec(1, 0)], x[I + vec(0, 1)], x[I + vec(1, 1)])
@ti.func
def backtrace(I, dt):
p = (I + stagger) * dx
#p = I * dx
if ti.static(rk == 1):
p -= dt * velocity(p)
elif ti.static(rk == 2):
p_mid = p - 0.5 * dt * velocity(p)
p -= dt * velocity(p_mid)
elif ti.static(rk == 3):
v1 = velocity(p)
p1 = p - 0.5 * dt * v1
v2 = velocity(p1)
p2 = p - 0.75 * dt * v2
v3 = velocity(p2)
p -= dt * (2 / 9 * v1 + 1 / 3 * v2 + 4 / 9 * v3)
else:
ti.static_print(f"RK{rk} is not supported.")
return p
@ti.func
def semi_lagrangian(x, new_x, dt):
# Note: this loop is parallelized
for I in ti.grouped(x):
new_x[I] = sample_bilinear(x, backtrace(I, dt))
# Reference: https://github.com/ziyinq/Bimocq/blob/master/src/bimocq2D/BimocqSolver2D.cpp
@ti.func
def maccormack(x, dt):
semi_lagrangian(x, new_x, dt)
semi_lagrangian(new_x, new_x_aux, -dt)
for I in ti.grouped(x):
new_x[I] = new_x[I] + 0.5 * (x[I] - new_x_aux[I])
if ti.static(mc_clipping):
source_pos = backtrace(I, dt)
min_val = sample_min(x, source_pos)
max_val = sample_max(x, source_pos)
if new_x[I] < min_val or new_x[I] > max_val:
new_x[I] = sample_bilinear(x, source_pos)
@ti.kernel
def advect():
if ti.static(use_mc):
maccormack(x, dt)
else:
semi_lagrangian(x, new_x, dt)
for I in ti.grouped(x):
x[I] = new_x[I]
paint()
gui = ti.GUI('Advection schemes', (512, 512))
while True:
while gui.get_event(ti.GUI.PRESS):
if gui.event.key in [ti.GUI.ESCAPE, ti.GUI.EXIT]: exit(0)
if gui.event.key == ti.GUI.SPACE:
pause = not pause
if not pause:
for i in range(1):
advect()
gui.set_image(x.to_numpy())
gui.show()
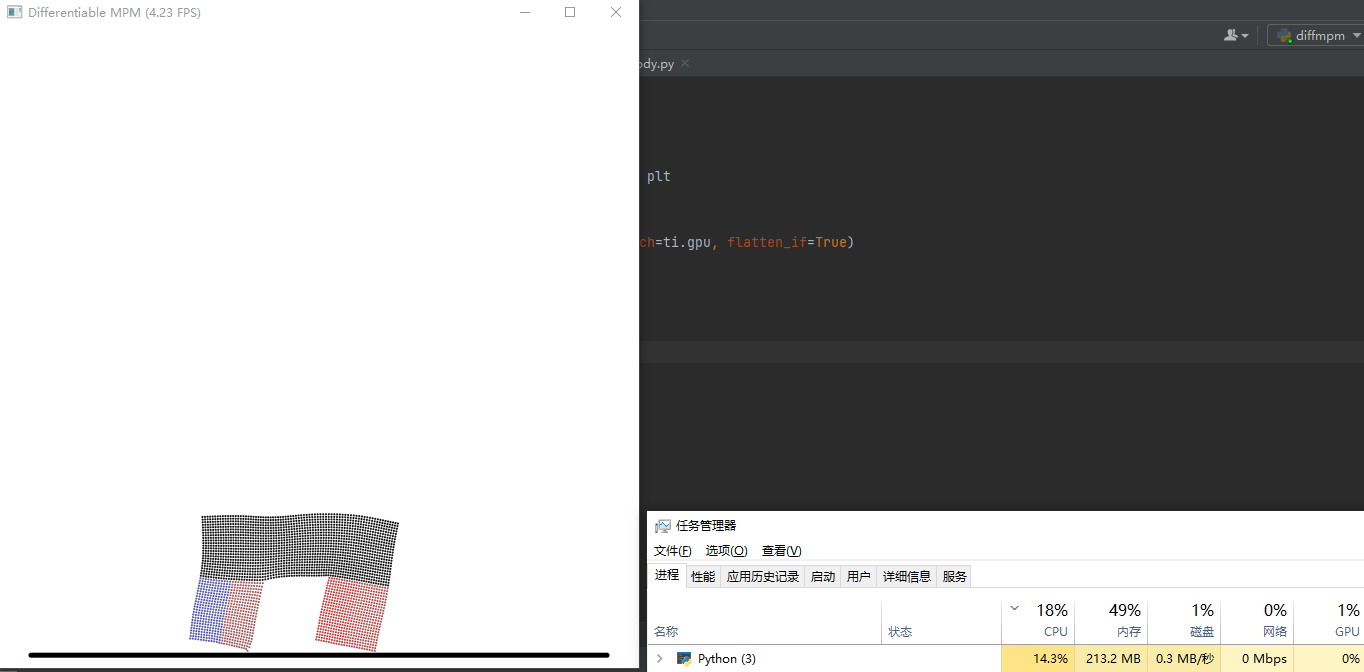
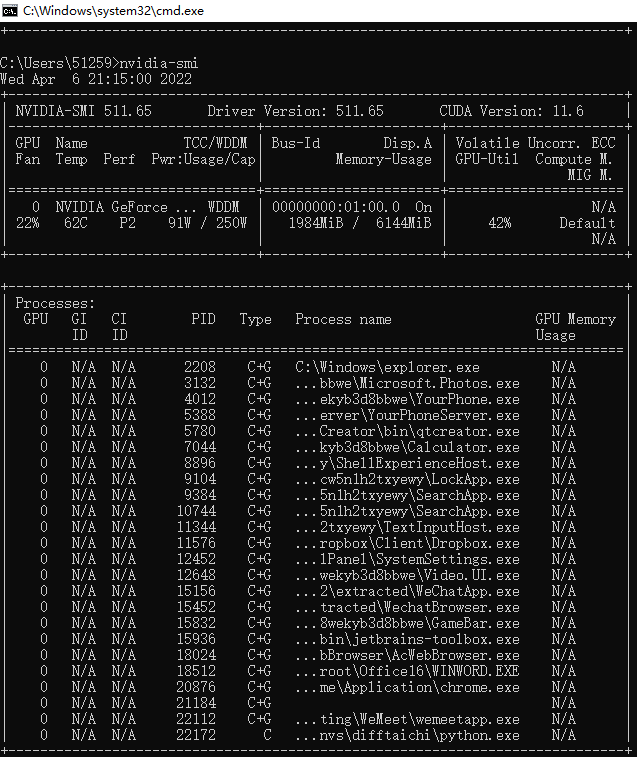
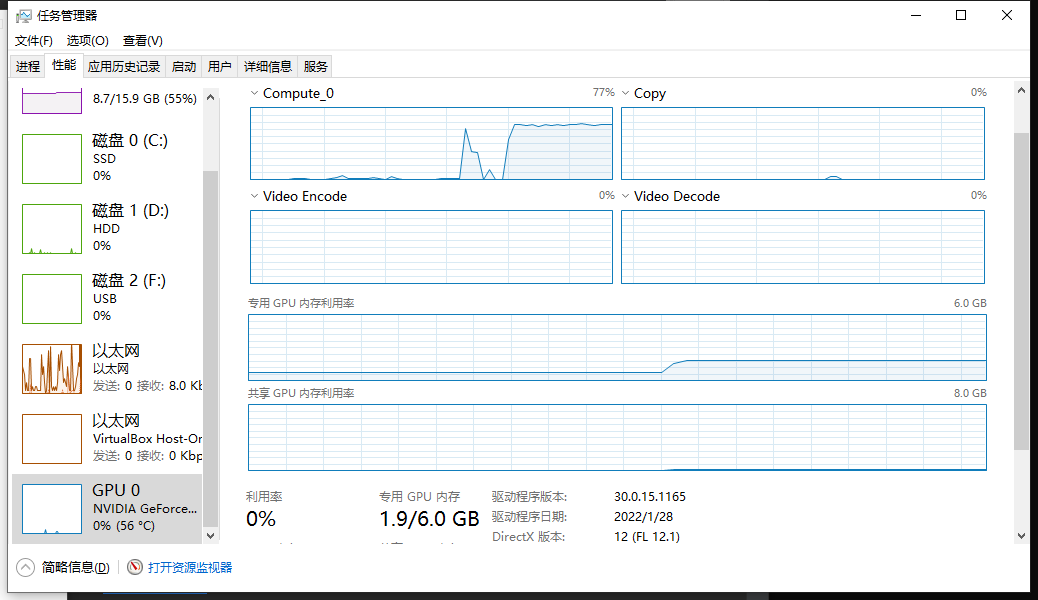
GPU利用率0%是什么原因呢