Hi,
I have installed taichi 0.6.6 from pip on Windows 10 ver 2004, running Python 3.8.2. I have RX 590 as the GPU and running the examples with OpenGL backend gives me black windows.
It is not completely black though. Running the waterwave example, there would something near the left edge. Running the nbody example, there are some blue pixels. Initalization with debug=True reveals no error message. By the way, GPU was being utilized (can be seen from task manager)
And I have even finished a build from source, and no luck there either. I have tested with PyOpenGL to confirm that OpenGL or my graphics card is fine. Any hint on what’s happening?
I can only post one image (PS: the low FPS in the image is probably due to me taking the screenshot just after dragging the window around, after stabilizing, it would be up to 60 fps):
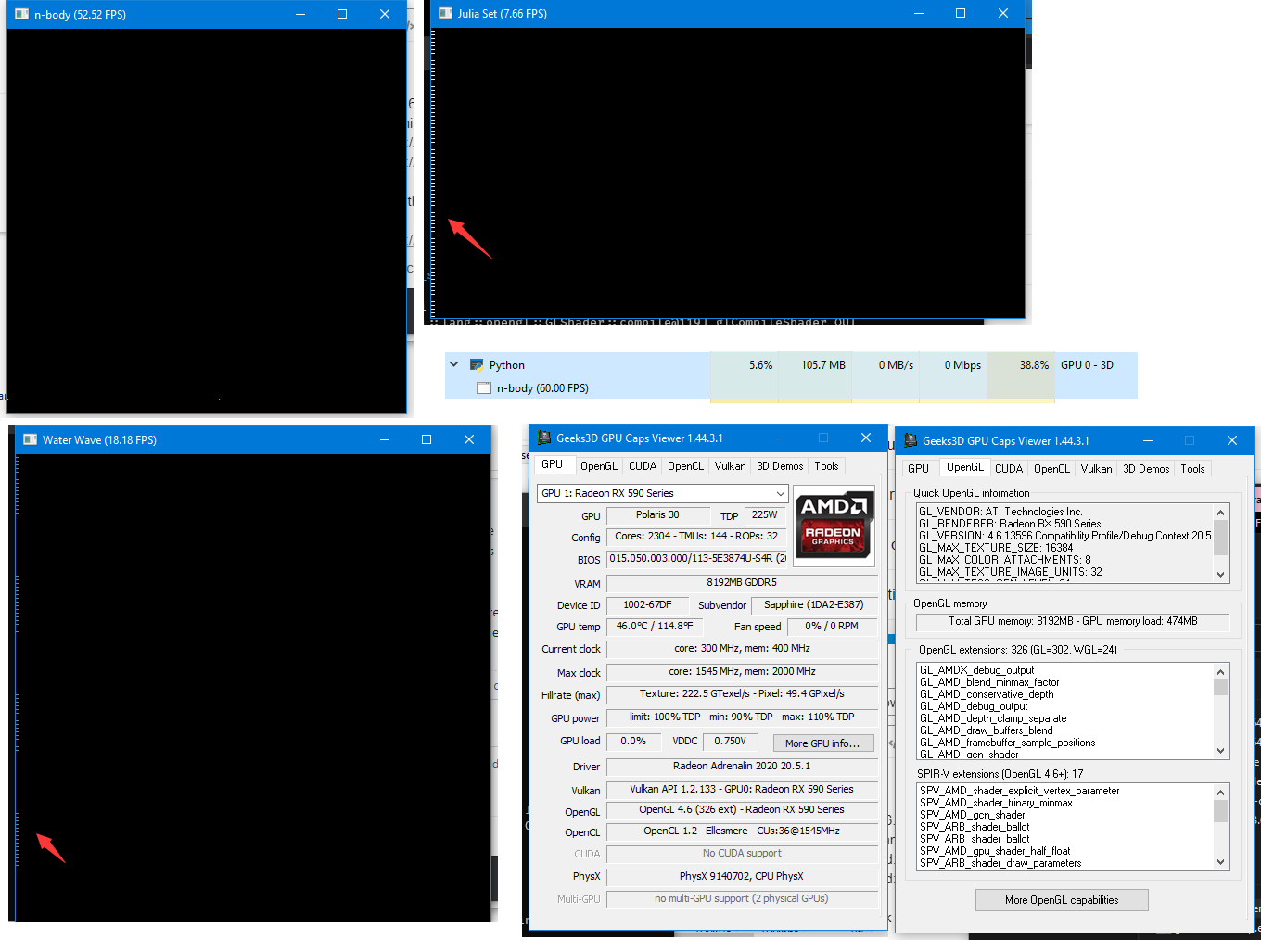
Here is the debug dump when I run the nbody oscillator example:
PS F:\taichi\examples> python .\nbody_oscillator.py
[Taichi] mode=release
[Taichi] version 0.6.6, supported archs: [cpu, opengl], commit 5cab3f28, python 3.8.2
[T 05/29/20 22:21:13.559] [program.cpp:taichi::lang::Program::Program@48] Program initializing…
[T 05/29/20 22:21:13.559] [memory_pool.cpp:taichi::lang::MemoryPool::MemoryPool@9] Memory pool created. Default buffer size per allocator = 1024 MB
[T 05/29/20 22:21:13.559] [llvm_context.cpp:taichi::lang::TaichiLLVMContext::TaichiLLVMContext@46] Creating Taichi llvm context for arch: x64
[T 05/29/20 22:21:13.560] [llvm_context.cpp:taichi::lang::TaichiLLVMContext::get_this_thread_data@620] Creating thread local data for thread 15772
[T 05/29/20 22:21:13.560] [llvm_context.cpp:taichi::lang::TaichiLLVMContext::TaichiLLVMContext@71] Taichi llvm context created.
[W 05/29/20 22:21:13.560] [program.cpp:taichi::lang::Program::Program@126] Out-of-bound access checking is only implemented on CPUs backends for now.
[T 05/29/20 22:21:13.561] [program.cpp:taichi::lang::Program::Program@134] Program (0x20ccb2eff50) arch=opengl initialized.
[D 05/29/20 22:21:13.561] [snode.cpp:taichi::lang::SNode::create_node@51] Non-power-of-two node size 8000 promoted to 8192.
[D 05/29/20 22:21:13.562] [snode.cpp:taichi::lang::SNode::create_node@51] Non-power-of-two node size 8000 promoted to 8192.
[T 05/29/20 22:21:13.581] [C:\Users\bowen\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:materialize@256] Materializing layout…
[T 05/29/20 22:21:13.951] [program.cpp:taichi::lang::Program::materialize_layout@279] materialize_layout called
[T 05/29/20 22:21:13.951] [program.cpp:taichi::lang::Program::materialize_layout@304] OpenGL root buffer size: 131072 B
[T 05/29/20 22:21:13.957] [C:\Users\bowen\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:call@463] Compiling kernel initialize_c4_0…
[T 05/29/20 22:21:13.969] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[T 05/29/20 22:21:13.970] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[T 05/29/20 22:21:13.971] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[D 05/29/20 22:21:13.972] [opengl_api.cpp:taichi::lang::opengl::display_kernel_info@347] source of kernel [initialize_c4_00] * 8:
#version 430 core
#extension GL_ARB_compute_shader: enable
#extension GL_NV_shader_atomic_int64: enable
precision highp float;
layout(packed, binding = 6) buffer runtime { int rand_state; };
layout(packed, binding = 0) buffer data_i32 { int data_i32[]; };
layout(packed, binding = 0) buffer data_f32 { float data_f32[]; };
layout(packed, binding = 0) buffer data_f64 { double data_f64[]; };
uvec4 rand; void _init_rand() { uint i = (54321 + gl_GlobalInvocationID.x) * (12345 + rand_state); rand.x = 123456789 * i * 1000000007; rand.y = 362436069; rand.z = 521288629; rand.w = 88675123; rand_state += 1; } uint _rand_u32() { uint t = rand.x ^ (rand.x << 11); rand.xyz = rand.yzw; rand.w = (rand.w ^ (rand.w >> 19)) ^ (t ^ (t >> 8)); return rand.w * 1000000007; } float _rand_f32() { return float(_rand_u32()) * (1.0 / 4294967296.0); } double _rand_f64() { return double(_rand_f32()); } int _rand_i32() { return int(_rand_u32()); }
void initialize_c4_00()
{ // range for
// range known at compile time
int _tid = int(gl_GlobalInvocationID.x);
if (_tid >= 8000) return;
int _itv = 0 + _tid * 1;
int I = _itv;
float J = _rand_f32();
float K = 0.5;
float L = J * K;
float M = 0.25;
float N = L - M;
float P = N + K;
int R = 0;
int S = 0;
int T = R + 131072 * S; // S0
int U = T + 0; // S1
int V = (((0 + I) >> 0) & ((1 << 13) - 1));
int Z = U + 8 * V; // S1
int Aq = Z + 0; // S2
data_f32[Aq >> 2] = P;
float As = _rand_f32();
int At = 2;
float Au = float(At);
float Av = As * Au;
int Aw = 1;
float Ax = float(Aw);
float Ay = Av - Ax;
int AA = T + 65536; // S4
int AB = AA + 8 * V; // S4
int AC = AB + 0; // S5
data_f32[AC >> 2] = Ay;
float AE = _rand_f32();
float AG = AE * K;
float AI = AG - M;
float AK = AI + K;
int AM = Z + 4; // S3
data_f32[AM >> 2] = AK;
float AO = _rand_f32();
float AP = AO * Au;
float AQ = AP - Ax;
int AS = AB + 4; // S6
data_f32[AS >> 2] = AQ;
}void main()
{
_init_rand();
initialize_c4_00();
}
layout(local_size_x = 1024 /* 8, 8000 */, local_size_y = 1, local_size_z = 1) in;[T 05/29/20 22:21:13.975] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@117] glCompileShader IN
[T 05/29/20 22:21:13.975] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@119] glCompileShader OUT
[T 05/29/20 22:21:13.975] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@157] glLinkProgram IN
[T 05/29/20 22:21:13.976] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@159] glLinkProgram OUT
[T 05/29/20 22:21:14.014] [C:\Users\bowen\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:call@463] Compiling kernel matrix_to_ext_arr_c16_0…
[T 05/29/20 22:21:14.021] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[T 05/29/20 22:21:14.021] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[T 05/29/20 22:21:14.022] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[D 05/29/20 22:21:14.022] [opengl_api.cpp:taichi::lang::opengl::display_kernel_info@347] source of kernel [matrix_to_ext_arr_c16_00] * 8:
#version 430 core
#extension GL_ARB_compute_shader: enable
#extension GL_NV_shader_atomic_int64: enable
precision highp float;
layout(packed, binding = 6) buffer runtime { int rand_state; };
layout(packed, binding = 0) buffer data_i32 { int data_i32[]; };
layout(packed, binding = 0) buffer data_f32 { float data_f32[]; };
layout(packed, binding = 0) buffer data_f64 { double data_f64[]; };
layout(packed, binding = 2) buffer args_i32 { int args_i32[]; };
layout(packed, binding = 2) buffer args_f32 { float args_f32[]; };
layout(packed, binding = 2) buffer args_f64 { double args_f64[]; };
layout(packed, binding = 3) buffer earg_i32 { int earg_i32[]; };
layout(packed, binding = 4) buffer extr_i32 { int extr_i32[]; };
layout(packed, binding = 4) buffer extr_f32 { float extr_f32[]; };
layout(packed, binding = 4) buffer extr_f64 { double extr_f64[]; };void matrix_to_ext_arr_c16_00()
{ // range for
// range known at compile time
int _tid = int(gl_GlobalInvocationID.x);
if (_tid >= 8192) return;
int _itv = 0 + _tid * 1;
int Av = 0;
int Au = 1;
int G = _itv;
int H = (((0 + G) >> 0) & ((1 << 13) - 1));
int I = 8000;
int J = int(H < I);
if (J != 0) {
int M = 0;
int O = M + 131072 * Av; // S0
int P = O + 0; // S1
int T = P + 8 * H; // S1
int U = T + 0; // S2
float V = data_f32[U >> 2];
int W = args_i32[0 << 1]; // is ext pointer float
int _li_Z = 0;
{ // linear seek
int _s0_Z = earg_i32[0 * 8 + 0];
int _s1_Z = earg_i32[0 * 8 + 1];
int _s2_Z = earg_i32[0 * 8 + 2];
_li_Z *= _s0_Z;
_li_Z += H;
_li_Z *= _s1_Z;
_li_Z += Av;
_li_Z *= _s2_Z;
_li_Z += Av;
}
int Z = W + (_li_Z << 2);
extr_f32[Z >> 2] = V;
int As = T + 4; // S3
float At = data_f32[As >> 2];
int _li_Aw = 0;
{ // linear seek
int _s0_Aw = earg_i32[0 * 8 + 0];
int _s1_Aw = earg_i32[0 * 8 + 1];
int _s2_Aw = earg_i32[0 * 8 + 2];
_li_Aw *= _s0_Aw;
_li_Aw += H;
_li_Aw *= _s1_Aw;
_li_Aw += Au;
_li_Aw *= _s2_Aw;
_li_Aw += Av;
}
int Aw = W + (_li_Aw << 2);
extr_f32[Aw >> 2] = At;
}
}void main()
{
matrix_to_ext_arr_c16_00();
}
layout(local_size_x = 1024 /* 8, 8192 */, local_size_y = 1, local_size_z = 1) in;[T 05/29/20 22:21:14.026] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@117] glCompileShader IN
[T 05/29/20 22:21:14.026] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@119] glCompileShader OUT
[T 05/29/20 22:21:14.026] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@157] glLinkProgram IN
[T 05/29/20 22:21:14.027] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@159] glLinkProgram OUT
[T 05/29/20 22:21:14.036] [C:\Users\bowen\AppData\Local\Programs\Python\Python38\lib\site-packages\taichi\lang\kernel.py:call@463] Compiling kernel advance_c6_0…
[T 05/29/20 22:21:14.074] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[T 05/29/20 22:21:14.081] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[T 05/29/20 22:21:14.083] [constant_fold.cpp:taichi::lang::irpass::constant_fold@208] config.debug enabled, ignoring constant fold
[D 05/29/20 22:21:14.084] [opengl_api.cpp:taichi::lang::opengl::display_kernel_info@347] source of kernel [advance_c6_00] * 8:
#version 430 core
#extension GL_ARB_compute_shader: enable
#extension GL_NV_shader_atomic_int64: enable
precision highp float;
layout(packed, binding = 6) buffer runtime { int rand_state; };
layout(packed, binding = 0) buffer data_i32 { int data_i32[]; };
layout(packed, binding = 0) buffer data_f32 { float data_f32[]; };
layout(packed, binding = 0) buffer data_f64 { double data_f64[]; };
layout(packed, binding = 2) buffer args_i32 { int args_i32[]; };
layout(packed, binding = 2) buffer args_f32 { float args_f32[]; };
layout(packed, binding = 2) buffer args_f64 { double args_f64[]; };void advance_c6_00()
{ // range for
// range known at compile time
int tid = int(gl_GlobalInvocationID.x);
if (tid >= 8000) return;
int itv = 0 + tid * 1;
float Cx = 0.000233;
float Cv = 1e-06;
int C3 = 0;
int BY = 1;
float Bz = -0.8;
int K = itv;
int M = 0;
int O = M + 131072 * C3; // S0
int P = O + 0; // S1
int Q = (((0 + K) >> 0) & ((1 << 13) - 1));
int U = P + 8 * Q; // S1
int V = U + 0; // S2
float W = data_f32[V >> 2];
int Y = O + 65536; // S4
int Z = Y + 8 * Q; // S4
int Aq = Z + 0; // S5
float Ar = data_f32[Aq >> 2];
float At = float(C3);
int Au = int(W < At);
int Aw = BY & Au;
int Ax = int(Ar < At);
int Az = BY & Ax;
int AA = Aw & Az;
float AC = float(BY);
int AD = int(W > AC);
int AF = BY & AD;
int AG = int(Ar > At);
int AI = BY & AG;
int AJ = AF & AI;
int AK = AA | AJ;
float AZ = Bz * Ar;
if (AK != 0) {
data_f32[Aq >> 2] = AZ;
}
int B2 = U + 4; // S3
float B3 = data_f32[B2 >> 2];
int B5 = Z + 4; // S6
float B6 = data_f32[B5 >> 2];
int B7 = int(B3 < At);
int B9 = BY & B7;
int Ba = int(B6 < At);
int Bc = BY & Ba;
int Bd = B9 & Bc;
int Be = int(B3 > AC);
int Bg = BY & Be;
int Bh = int(B6 > At);
int Bj = BY & Bh;
int Bk = Bg & Bj;
int Bl = Bd | Bk;
float BA = Bz * B6;
if (Bl != 0) {
data_f32[B5 >> 2] = BA;
}
float BC = 0.5;
float BD = W - BC;
float BF = B3 - BC;
float BG = BD * BD;
float BH = BF * BF;
float BI = BG + BH;
float BJ = BI + At;
float BK = float(sqrt(BJ));
float BL = -80.0;
float BM = BL * BK;
float BN = 0;
float BO = BD * BM;
BN = BO;
float BQ = 0;
float BR = BF * BM;
BQ = BR;
int BU = 8000;
for (int BV = C3; BV < BU; BV = BV + 1) {
int BV = BV;
int BW = BV;
int BX = int(K != BW);
int BZ = BY & BX;
int C2 = 0;
int C4 = C2 + 131072 * C3; // S0
int C5 = C4 + 0; // S1
int C6 = (((0 + K) >> 0) & ((1 << 13) - 1));
int Ca = C5 + 8 * C6; // S1
int Cb = Ca + 0; // S2
float Cc = data_f32[Cb >> 2];
int Ce = (((0 + BW) >> 0) & ((1 << 13) - 1));
int Ch = C5 + 8 * Ce; // S1
int Ci = Ch + 0; // S2
float Cj = data_f32[Ci >> 2];
float Ck = Cc - Cj;
int Cm = Ca + 4; // S3
float Cn = data_f32[Cm >> 2];
int Cp = Ch + 4; // S3
float Cq = data_f32[Cp >> 2];
float Cr = Cn - Cq;
float Cs = Ck * Ck;
float Ct = Cr * Cr;
float Cu = Cs + Ct;
float Cw = Cv + Cu;
float Cy = Cx / Cw;
float Cz = BN;
float CA = Ck * Cy;
float CB = Cz + CA;
float Q8 = (BZ) != 0 ? (CB) : (Cz);
BN = Q8;
float CD = BQ;
float CE = Cr * Cy;
float CF = CD + CE;
float Qa = (BZ) != 0 ? (CF) : (CD);
BQ = Qa;
}
float CH = data_f32[Aq >> 2];
float CI = args_f32[0 << 1];
float CJ = CH * CI;
float CK = W + CJ;
data_f32[V >> 2] = CK;
float CM = data_f32[B5 >> 2];
float CN = CM * CI;
float CO = B3 + CN;
data_f32[B2 >> 2] = CO;
float CQ = BN;
float CR = CQ * CI;
float CS = CH + CR;
data_f32[Aq >> 2] = CS;
float CU = BQ;
float CV = CU * CI;
float CW = CM + CV;
data_f32[B5 >> 2] = CW;
}void main()
{
advance_c6_00();
}
layout(local_size_x = 1024 /* 8, 8000 */, local_size_y = 1, local_size_z = 1) in;[T 05/29/20 22:21:14.091] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@117] glCompileShader IN
[T 05/29/20 22:21:14.091] [opengl_api.cpp:taichi::lang::opengl::GLShader::compile@119] glCompileShader OUT
[T 05/29/20 22:21:14.102] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@157] glLinkProgram IN
[T 05/29/20 22:21:14.103] [opengl_api.cpp:taichi::lang::opengl::GLProgram::link@159] glLinkProgram OUT