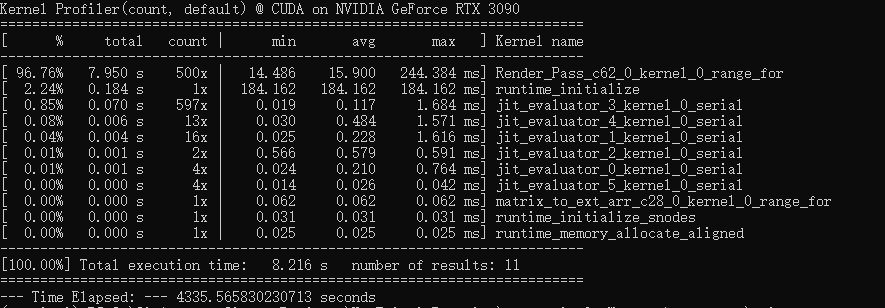
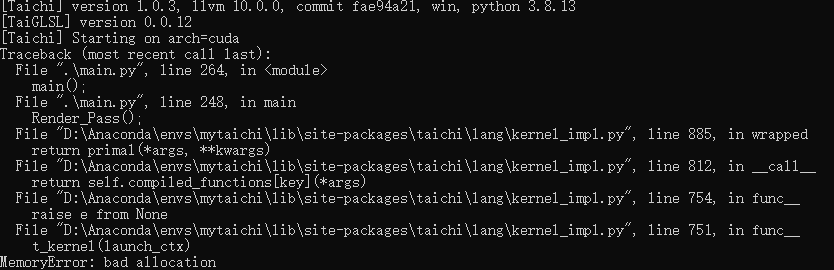
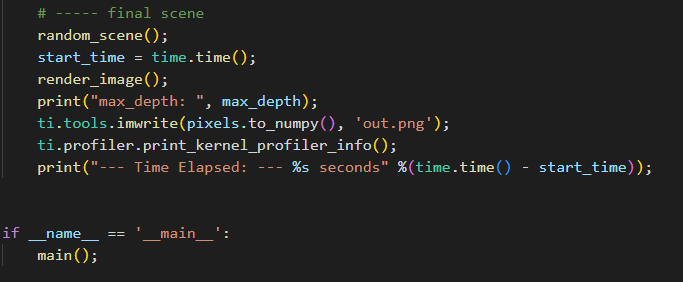
最近参考太极图形课和Ray tracing in one weekend 试着在taichi 利用ti.struct_class 复刻Ray tracing in One Weekend的结果,渲染结果是完全匹配的。唯一不解的是仿佛并没有成功地把加速体现出来,CUDA中运行时间为1秒左右,实际程序运行了30s, 具体可见如下图。整体代码文件可见该链接
谢谢!
最近参考太极图形课和Ray tracing in one weekend 试着在taichi 利用ti.struct_class 复刻Ray tracing in One Weekend的结果,渲染结果是完全匹配的。唯一不解的是仿佛并没有成功地把加速体现出来,CUDA中运行时间为1秒左右,实际程序运行了30s, 具体可见如下图。整体代码文件可见该链接
谢谢!
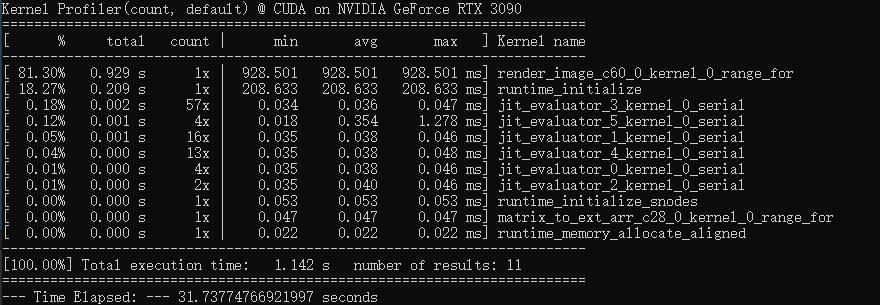
谢谢解答!不过感觉还挺有趣的,我今天参考Nvidia 的blog,复刻了C++ Cuda 版本的,在Nvidia 3090的机器上,整个程序19s 就跑完了封面的图片。在Taichi中跑的话,从Kernel Profile能看出其实是很接近的,结果这实际程序运行的时间是一个小时多了。
我有看到论坛里有其他相似的帖子提到这个类似问题,我也放到这里:
https://forum.taichi-lang.cn/t/2-another-ray-tracer/1858
https://github.com/0xrabbyte/TinyRayTracer-Taichi
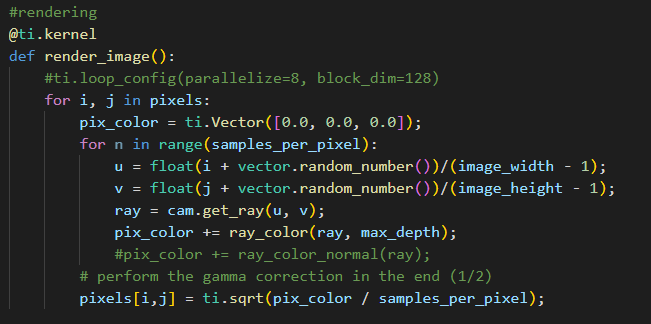
个人感觉可能涉及CPU和GPU数据之间传输同步相关? 我确实在taichi function的实现中涉及到了不少通过ti.struct_class进行诸如ray和hitting record的反复生成。但确实从实现上的high-level来看,都是基于面向对象设计的代码结构,确实不是很能理解用Taichi加速与用CUDA本身加速这个ray tracing项目的差距
我用taichi example 测试了一下感觉确实如果涉及比较复杂的场景,整体程序的时长完全停留在编译阶段的感觉,那请问如何能够尽量减少这个问题呢,尽量kernel 程序部分缩小化?主要是现在ray tracing 大场景多次运行成本太高了,改一两个语句,可能就涉及一两个小时的编译的话,有一些痛苦 ![]()
Hi,你提出的问题很好。目前Taichi在开发大型程序时,确实存在修改一两行代码就要重新编译的问题。社区中提出的一个方案是将未改动的部分放在cache里面,目前该功能正在开发中,具体请看:Issues · taichi-dev/taichi · GitHub
关于你的程序里面为何和CUDA程序差别这么大,恐怕我们还得测试一下。